Recap of Weight Decay (WD)
Recently, when training models, we mostly use Weight Decay (WD). There are many benefits to using WD, and a representative effect is preventing overfitting. Then, what is WD, and how can it prevent overfitting?
Generally, when encountering Deep Learning for the first time, you probably learn WD as follows:
\[\begin{equation} \mathcal{L}_{total}= \textcolor{red}{\underbrace{\frac{1}{n}\sum_{i=0}^n \ell(f(x_i;\theta), y_i)}_{\text{Loss Function }(\mathcal{L}(\theta))}} + \textcolor{blue}{\underbrace{\frac{\lambda}{2}||\theta||_2}_{\text{WD}}} \label{eq:weight_decay} \end{equation}\]In other words, when training through the Loss Function as shown above, we train in a direction that reduces the norm value of the model’s weight parameter in addition to the existing derived loss. When this happens, intuitively, it sends most weight parameters close to 0, reducing the model’s complexity, and through this, we can see the effect of preventing overfitting.
However, here we need to examine the role of WD a bit deeper. The reason is that the role of WD is not limited simply to ‘preventing Overfitting’. For example, recently WD is essentially applied even to very large models like LLMs. If you think about it, since LLMs are trained for about 1 epoch on very large datasets, there is essentially no need to consider overfitting. Nevertheless, we often proceed by applying an (even) larger WD ratio $\lambda$.
Therefore, in this post, I will try to explain the role of WD and its significance as I see it.
1) WD is actually a Prior Knowledge Distribution!
There is one ‘representative assumption’ commonly used when doing statistical modeling in the deep learning field. When setting a distribution, we assume it follows the Gaussian Distribution, which is the easiest to handle. The reason is simple. The normal distribution can perfectly define the entire distribution knowing only the Mean and Variance without complex parameters. Therefore, before the full-scale explanation, I will also proceed with the following assumption:
Assumption: Model weight parameters follow a Gaussian distribution.
If the above assumption holds, we can derive the following statement:
WD is a Maximum A Posteriori (MAP) estimation assuming the weights have a Gaussian prior.
Then, let’s examine slowly what this means. Here, we will look at deep learning training not from an optimization perspective, but from a probability perspective of finding the optimal solution.
(This content was written by synthesizing the contents of PRML Chapter 3.3 and various other materials.)
Expansion of concept from MLE to MAP
Usually, during training, we aim to find the model parameter $\theta$ that minimizes the Loss Function (e.g., MSE, CE). In statistical terms, this is called Maximum Likelihood Estimation (MLE). MLE is an estimation method from the data perspective; simply put, it means “Let’s estimate $\theta$ that can maximize the probability $p(\mathcal{D} \mid \theta)$ that the given dataset $\mathcal{D}$ is observed”. Expressing this MLE as a formula gives:
\[\begin{equation} \theta_{\text{MLE}} = \arg\max_{\theta} p(\mathcal{D} \mid \theta) \end{equation}\]I think most of you know this formula; it is the Loss Function we usually represent. That is, if we substitute the above MLE into a minimization problem by attaching a $-$, it becomes the Loss Function $\mathcal{L}(\theta)$ we usually use.
(Returning to the main point) However, although MLE is the most universal, it has a downside. It is the point that it relies entirely on the observed dataset $\mathcal{D}$. Let me explain with an example. Let’s say we found the optimal $\theta^\ast$ for a specific dataset $\mathcal{D}_1$. Even if this $\theta^\ast$ is optimal in $\mathcal{D}_1$, it might not be the optimal solution for a new $\mathcal{D}_2$ where the data distribution is slightly different. In other words, when the given data is too small or biased, MLE tries to learn by excessively fitting to the characteristics (even noise) of that data, and this becomes the fundamental cause of what we commonly call overfitting.
Then, to prevent overfitting, what if we make an assumption (prior) about $\theta$ before seeing $\mathcal{D}$? In other words, if we proceed with training looking only at $\mathcal{D}$, problems may arise when deviating too much from that data distribution, so it means “How about defining the $\theta$ we want to find optimally in advance before seeing $\mathcal{D}$?”. Here, we view it from a Bayesian perspective. That is, we consider the prior for $\theta$ before seeing $\mathcal{D}$, and this is called Maximum A Posteriori (MAP) estimation. Expressing this as a formula gives:
\[\begin{equation} \theta_{\text{MAP}} = \arg\max_\theta p(\theta \mid \mathcal{D}) \end{equation}\]Here, $p(\theta \mid \mathcal{D})$ can be expanded as follows by Bayes’ theorem:
\[\begin{equation} \theta_{\text{MAP}} = \arg\max_\theta \frac{p(\mathcal{D} \mid \theta) p (\theta)}{p(\mathcal{D})} \end{equation}\]The equation above changes into a problem of maximizing the product of $p(\mathcal{D}\mid \theta)$ (Likelihood) and $p(\theta)$ (Prior). And here, since $p(\mathcal{D})$ can be treated as a constant we already know, there is no need to consider it. Now then, how can we treat $p(\theta)$ as a prior and solve the problem?
Prior Knowledge: Gaussian Prior $\mathbf{\theta}$
Now, let’s apply the assumption about the Gaussian prior mentioned earlier. Assuming $p(\theta)$ can be expressed as a probability distribution, and it follows the most standard $\mathcal{N}(0, \sigma^2)$, $\theta$ can be expressed with the following relation:
\[\begin{equation} \theta \sim \mathcal{N}(0, \sigma^2I) \;\; \Rightarrow \;\; p(\theta) \propto \exp(-\frac{\|\theta\|_2}{2\sigma^2}) \label{eq:prior_gaussian} \end{equation}\]Let’s substitute this assumption into the MAP equation. To simplify the calculation of the multiplication form, if we take the Log on both sides and attach a negative sign (-) again to substitute it into a Minimization problem, it becomes as follows:
\[\begin{aligned} \theta_{MAP} &= \arg\min_\theta \left[ -\log p(\mathcal{D}|\theta) - \log p(\theta) \right] \\ &= \arg\min_\theta \left[ \underbrace{\mathcal{L}(\theta)}_{=\text{MLE}} - \log \left( \exp\left( -\frac{||\theta||^2}{2\sigma^2} \right) \right) \right] \end{aligned}\]If we organize the equation above, as $\log$ and $\exp$ disappear, it can be represented as follows:
\[\begin{equation} \mathcal{L}= \textcolor{red}{\underbrace{\mathcal{L}(\theta)}_{=\text{MLE}}} + \textcolor{blue}{\underbrace{\frac{1}{2\sigma^2} ||\theta||^2}_{\text{Prior}}} \label{eq:map_min} \end{equation}\]Looking at this equation, it is very similar to the WD Eq.\eqref{eq:weight_decay} summarized above. Here, only $\frac{\lambda}{2}$ in Eq.\eqref{eq:weight_decay} and $\frac{1}{2\sigma^2}$ in Eq.\eqref{eq:map_min} are different, but the form is exactly the same. In other words, if $\lambda = \frac{1}{\sigma^2}$, they can be said to be perfectly equivalent.
Meaning of WD Ratio $\lambda$
The WD we conventionally used was not a simple technique, but a method approached with the concept that the weight parameter is a Prior following $\mathcal{N}(0, \sigma^2I)$ (Eq. $\eqref{eq:prior_gaussian}$).
Furthermore, it is important here that $\lambda$ and variance $\sigma^2$ are inversely proportional. Usually, when $\lambda$ is set too large, cases arise where training does not converge. Also, when $\lambda$ is set too small, we do not see the full effect of WD. Thinking about these cases in conjunction with variance $\sigma^2$ helps understand why this happens:
- $\lambda \uparrow$ $\Rightarrow$ $\sigma^2 \downarrow$ : A small variance of the Prior Distribution means the variables are heavily concentrated around 0. In this case, if the distribution of dataset $\mathcal{D}$ is large, it is difficult to find the optimal $\theta$.
- $\lambda \downarrow$ $\Rightarrow$ $\sigma^2 \uparrow$ : A large variance of the Prior Distribution means the variables are relatively well spread out. Therefore, in this case, since it effectively has a similar effect to almost no prior assumption being applied, the risk of overfitting still exists.
Understanding this role of Prior ($\lambda$) allows us to clearly understand why such strong WD is used in recent training settings of deep learning models, especially in modern models like Vision Transformer (ViT).
Generally, even when training Vision Transformer (ViT) on datasets like ImageNet, we often set a much higher $\lambda$ value than existing CNN models. This is to control the characteristics of ViT, that is, the ‘Degree of Freedom’ the model possesses. Unlike CNNs, ViT has almost no Inductive Bias (constraints) such as connectivity between pixels or Spatial Locality during training. In other words, it implies that the Hypothesis Space the Weight Parameter must search to find the optimal solution is very wide.
When the freedom of the space the weight searches is high during training like this, it is an advantage if there is infinite data, but it often becomes a disadvantage when data is limited. This is because it learns even the trivial noise of data, making it easy for overfitting to occur. If, at this time, we apply a constraint called Prior to the model parameter through WD, the effective space the weight needs to search becomes much narrower, and consequently, we can effectively prevent Overfitting.
Synthesizing this example and the formulas developed earlier, the conclusion is as follows. Conclusively, WD should not be viewed only as the role of a simple regularizer, but as a balanced process of finding the optimal solution by reflecting the Prior Distribution (Given Prior / Gaussian Distribution Assumption) we assumed onto the training that relies entirely on data (MLE).
2) WD in LLMs
The content above showed the connection between WD and overfitting. But in fact, WD is not used only to prevent overfitting. For example, as briefly mentioned above, strong WD is applied even in Large Language Model (LLM) training where overfitting does not need to be considered. Let’s see the reason for that. Here, we will look at deep learning training from an optimization perspective again.
(This content excerpts parts of Lecture 3 from Stanford CS336 LLM from Scratch.)
LLMs Only Train Once
First, we need to understand the training characteristics of LLMs. The goal of LLMs like GPT-3 and LLaMA is to become a Generalist performing various tasks, not a specific task, and for this, they learn vast amounts of data, enough to say they crawled the entire internet.
Since the data is so vast, it is common for LLMs to train for only 1 Epoch. It means they scan through the data only once without seeing the same data repeatedly. From this perspective, overfitting in the traditional sense is indeed not a matter of consideration in LLMs. Nevertheless, why do LLMs apply strong WD?
LLMs Need More Gradients
The reason lies in the interaction with Learning Rate (LR) Scheduling. Most recent LLM training uses scheduling like Cosine Decay. It is a method of increasing the LR through Warm-up in the early stages of training, then gradually decreasing it as training progresses, making it close to 0 at the very end.
The problem is the latter part of training. When the LR becomes very small, not only does the Step Size updating the weight decrease, but the influence of the gradient itself also becomes insignificant. In other words, there is a risk that the model stagnates without performing meaningful learning anymore.
Precisely from this perspective, the role of WD included in the loss term becomes important. Although this has not been very clearly defined, there is a phenomenon revealed experimentally through recent research/papers, and we can check the results through Figure 1 below. Looking closely at Figure 1, although the Training Loss value in the early part of training might be somewhat larger when strong WD is applied, we can verify that ultimately, the Training Loss value converges lower when larger WD is applied.

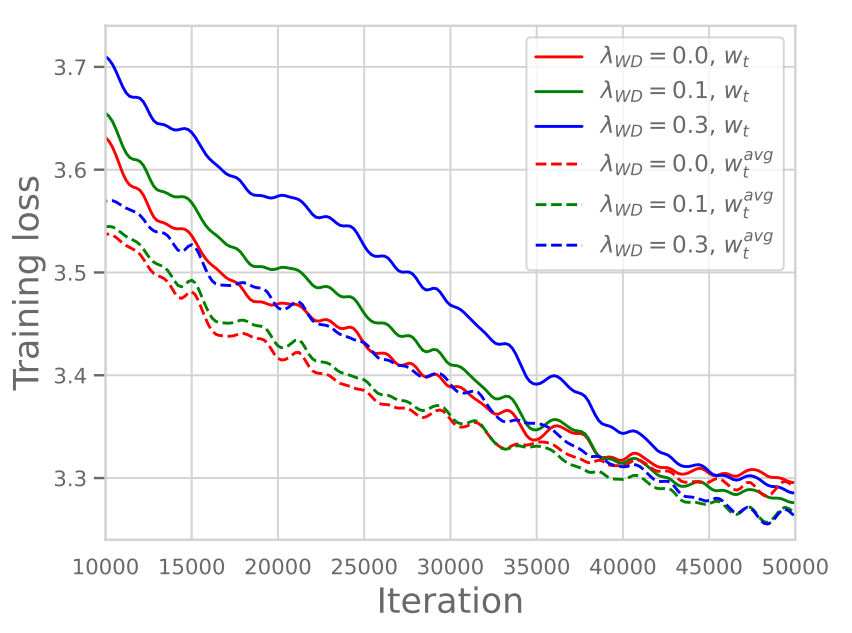
In that lecture, Professor Hashimoto interprets this as follows:
(Paraphrased)Due to LR Scheduling, the Learning Rate decreases as it goes towards the latter part of training, and accordingly, the Gradient also decreases, so the training effect may become insignificant at the very end of training. At this time, if we apply strong WD, it means it maintains the Gradient values at a certain magnitude even at the end of training, enabling continuous learning.
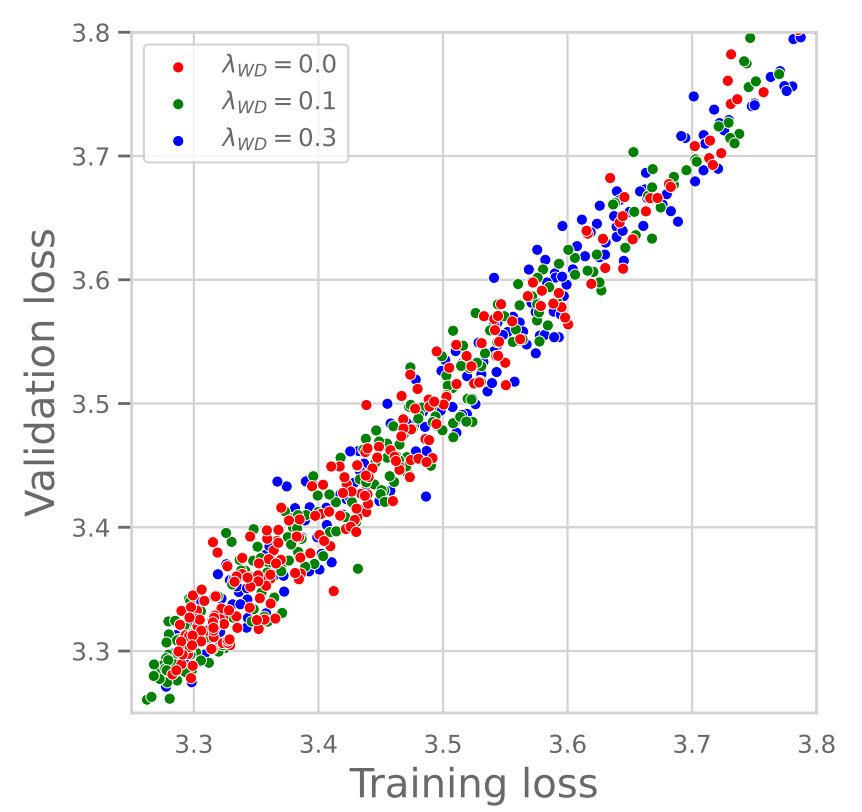
Research results supporting this are also shown in the paper as Figure 2 below.
First, looking at the graph on the left, it shows the relationship between Training & Validation Loss according to the WD value. As can be seen in the graph, the Training Loss and Validation Loss values appear almost identical regardless of whether the WD value is large or small. In other words, we can see that the Generalization Gap converges to almost 0 regardless of the WD size. This clearly shows that WD in LLM training is unrelated to preventing Overfitting (Generalization).
On the other hand, the graph on the right shows the result according to WD when using Constant LR (keeping Learning Rate constant without decreasing). Here, unlike Figure 1, we can verify that the Training Loss value rather increases as WD gets larger. In other words, in a situation where LR does not decrease, we can verify that applying strong WD acts simply as an effect of strongly constraining the Prior, rather causing harm to performance.
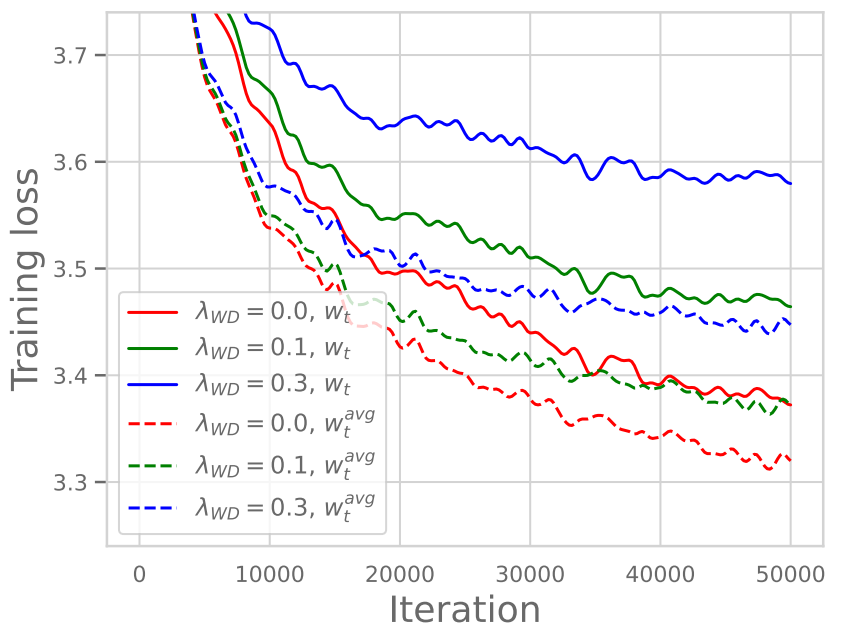
Synthesizing the contents above, it would be good to understand that WD in LLMs is used to maintain the continuity of training in conjunction with LR Scheduling, unlike the existing concept of preventing overfitting.
Conclusion
In conclusion, Weight Decay (WD) can be viewed from two perspectives: the Statistical Perspective and the Optimization Perspective:
- Viewed from the
Statistical Perspective, by introducing a Gaussian Prior to the MLE method which relies entirely on data and converting it to MAP estimation, it prevents data bias and allows finding a stable solution. - At the same time, from the
Optimization Perspective, it performs the role of guaranteeing the continuity of training by preserving the magnitude of the Gradient, which decreases as Learning Rate Decay progresses during large-scale training like LLMs.
In other words, WD can be defined as performing two core functions according to the setting: limiting the Hypothesis Space through Prior to search for the optimal solution from a statistical perspective and maintaining training momentum from an optimization perspective.
I have organized concepts used in deep learning after a long time. I will often post about concepts that are used frequently but whose beyond can be examined. Thank you for reading.
Reference
- Bishop, Christopher M. Pattern Recognition and Machine Learning. New York :Springer, 2006. (Original Book)
- Andriushchenko, Maksym, et al. “Why do we need weight decay in modern deep learning?.” ICLR (2023). (Paper)
- Stanford CS336 Lecture 3 (Youtube)