그럼에도 불구하고, Meta Learning의 개념과 그 실효성은 여전히 중요하다고 생각합니다. 특히,
따라서, Meta Learning, 또는 작은 범주에선 Few-Shot Learning에 대한 개념을 아는 것은 중요하다고 생각합니다. 관련된 특정 알고리즘들을 전부 다 알 필요는 없지만, Meta Learning을 활용 시 문제를 어떻게 정의하고 또 학습 setting을 어떻게 설정할지 등에 대해서 알면 더욱 다양하게 접근할 수 있지 않을까 생각이 돼서 이에 대해서 다뤄볼까 합니다!!
(위 서론이 너무 길었네요… 단도직입적으로 들어가겠습니다!! ![]() )
)
0. What is Meta Learning?
Meta Learning을 설명할 때, 많은 사람들이 “Learn to Learn”이라고 설명하는데, 쉽게 얘기하면 인간이 학습하는 방법이라고 생각하시면 됩니다. 인간은 살아가면서 다양한 경험을 쌓고, 이를 바탕으로 새로운 지식을 습득합니다. 이때, 인간은 기존에 알고 있던 지식과 새로운 경험을 결합하여 새로운 지식을 습득합니다. 꼭 A to Z까지 다 알려주지 않더라도 기존에 가지고 있던 지식들을 통해 유추할 수 있다는 것이죠.(물론 아예 새로운 것은 예외) 예를 들어, 처음에는 사과와 강아지를 구분하지 못하더라도, 몇 번의 경험을 통해 사과와 강아지의 특징을 파악하고, 이를 바탕으로 새로운 사과나 강아지를 구분할 수 있게 됩니다. 그리고 나중에는 강아지랑 비슷한 동물, 또는 사과와 비슷한 과일을 보더라도 구분할 수 있게 되죠. 이렇듯 인간은 ‘경험’을 통해 학습하는 능력을 가지고 있으며, Meta Learning은 이러한 인간의 학습 능력을 모방하여 deep learning 학습 방법에 적용한 것입니다.
1. Few-Shot Learning
그렇다면 이 process를 한번 AI model 학습 방법에 적용해봅시다.
우선 conventional한 deep learning을 생각해봅시다. 기존 deep learning은 아래 Figure 1 같이 각 class에 대해서 수많은 image들을 학습을 시켜야 합니다. 하지만 이렇게 학습할 경우 overfitting 등의 문제가 발생하게 되고, generalization 관점에서는 다양한 data를 더 투입하는 거 외에 다른 방법을 찾기 어렵습니다. 그러나 data는 언제나 한정돼있기 때문에 더 많은 data, 그리고 더욱 다양한 data를 모으는 것은 어려운 일이고 비효율적입니다. 그렇다면 deep learning을 인간처럼 효율적으로 학습을 하려면 어떻게 해야할까요? 이럴 때 도입하게 된 개념 중 하나가 “Few-Shot Learning“입니다.
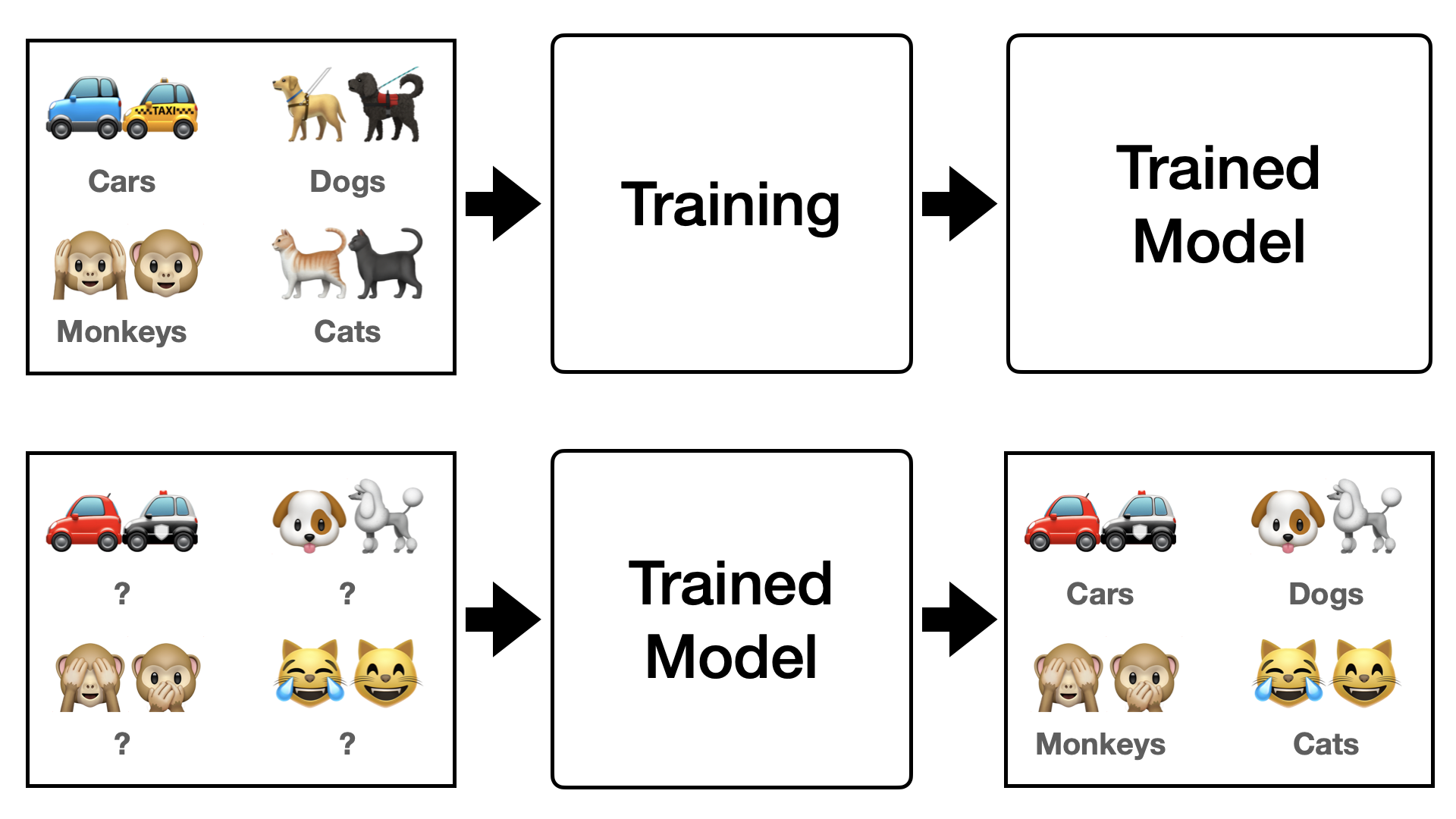
Few-shot learning을 간단하게 표현하면 a few data만 보고 학습하는 것입니다. 즉, 매 epoch마다 a few data만 보여주면서 학습을 시키는 방법입니다. 여기서 헷갈리시면 안되는게 a few data로만 학습을 하는 것이 아니라 전체 data 중 a few data만 추출해서 학습을 진행하는 것입니다. 그렇기에 setting 방법도 conventional deep learning 방법과는 조금 상이합니다. Few-Shot setting을 이해하기 위해서는 $N$-ways $K$-shots, 또 Support Set($S$) 과 Query Set($Q$)의 개념을 알아야합니다.
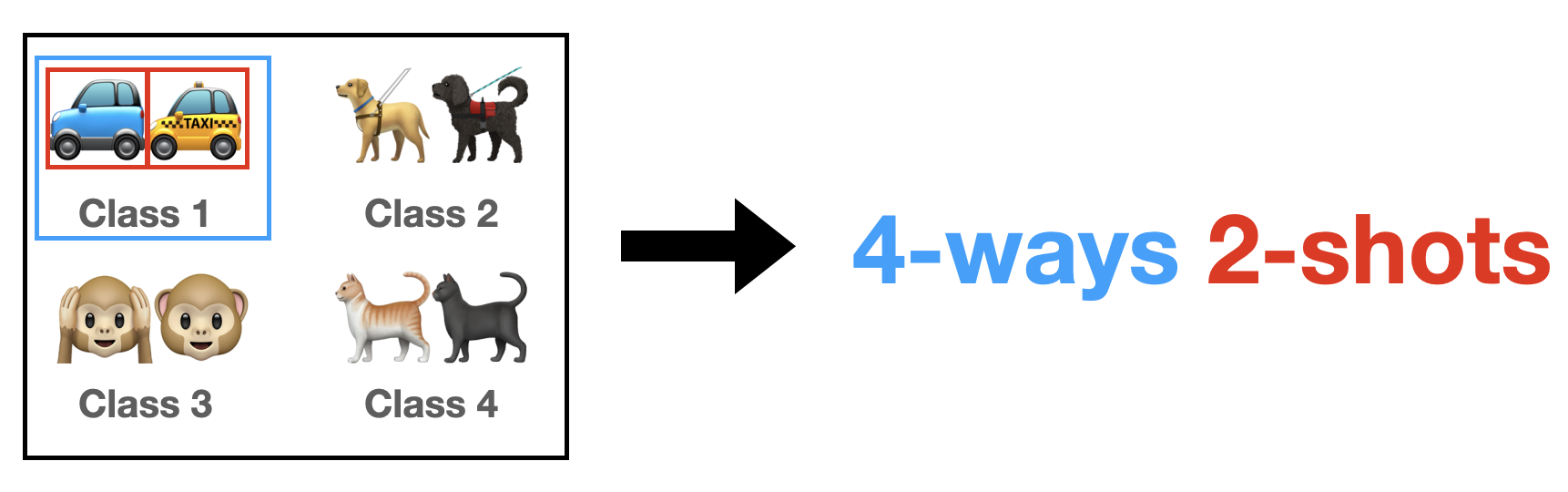
1.1 $N$-Ways $K$-Shots
여기서 $N$은 전체 datasets의 class들 중에서 추출할 class의 갯수를 의미합니다. (Figure 2) 그리고 여기서 $K$는 각 class 당 추출할 image의 갯수를 의미합니다. 예를 들어, 어떤 datasets의 전체 class가 100개라고 가정해보겠습니다. 그리고 실험 setting을 5-ways 1-shot으로 한다고 한다면, 매 epoch마다 100개의 class 중 5개의 class를 random하게 선택하고, 각 class마다 1개의 image를 추출하는 것입니다.
1.2 Support Set ($S$) and Query Set ($Q$)
우선 설명하기 앞서, $S$ 와 $Q$는 한 묶음으로 생각하셔야 합니다. AI community에서는 이 묶음을 episode 또는 task라고 표현합니다. 더 나아가서 few-shot learning을 때론 episodic learning이라고 표현하기도 합니다. 학습할 때 매 epoch마다 batch size만큼의 episode/task를 뽑습니다.
여기서 $S$는 method를 따라서 학습에 직접적으로 참여하는 data들이고 $Q$는 학습 후 얼마나 잘 학습 됐는지 evaluate할 때 사용하는 data들입니다. 아마 few-shot learning을 처음 접하시는 분들은 이 setting이 조금 헷갈리실 수도 있을 것입니다. 그래서 아래 Figure 3를 통해 설명드리도록 하겠습니다.
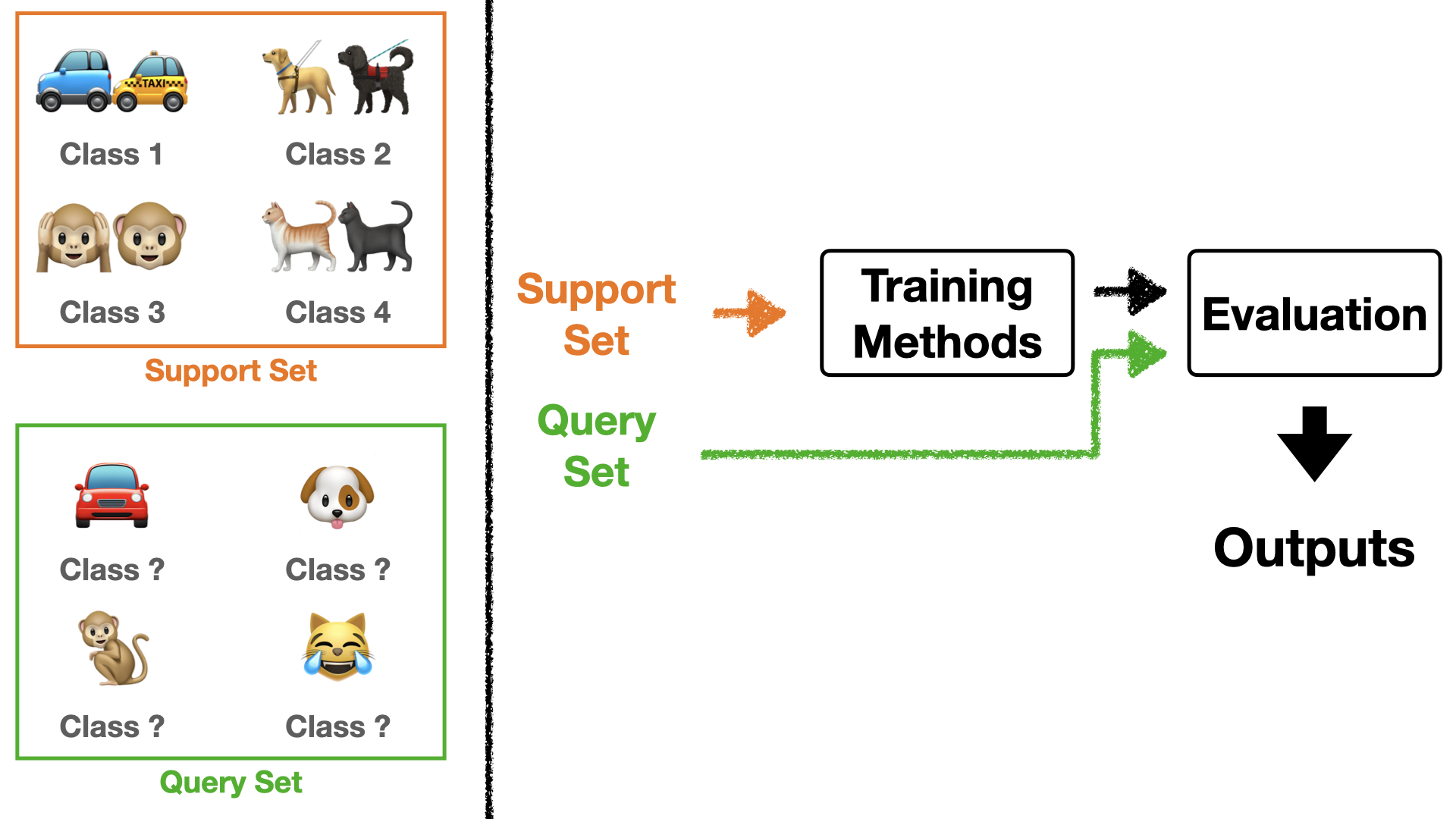
Figure 3을 보시면 $S$와 $Q$에 대한 예시가 왼쪽에 나와 있습니다. $S$는 어떤 class인지 아는 상태에서 학습에 참여합니다. 즉, $S$로 supervised learning처럼 model을 학습 시키는 것이죠. 그래서 $S$는 $N$-ways $K$-shots을 따릅니다. 그리고 $Q$는 어떤 class인지 모르는 상태에서 학습된 model에 넣어 나온 결과를 평가지표로써 활용합니다.
여기서 한가지 중요한 점은, $Q$는 $N$-ways는 따르지만, $K$-shots을 따르진 않습니다. 즉, $S$로 인해 class의 개수는 정해져 있지만 각 class 당 image의 개수는 정해져 있지 않습니다. 꼭 class 당 $K$개의 image를 뽑을 필요가 없다는 것이죠. 보통 query set은 각 class당 15개의 data를 뽑습니다.
추가로, 보통 $S$를 seen task, $Q$를 unseen task라고 표현하기도 합니다. 결국 few shot learning을 하는 이유는 unseen task에서 좋은 성능을 내기 위함이기에 $Q$로 update을 진행하는 것입니다.
1.3 Wrap-up
Few-shot learning에 대해서 정리하자면 다음과 같습니다:
- $N$-ways $K$-shots에 따른 task(= [$S$, $Q$])를 sampling한다
- $S$로 method에 따라 학습한다.
- $Q$로 학습이 잘 됐는지 평가한다.
- 3.에서 나온 결과로 최종 loss를 뽑는다
- 4.에서 나온 loss로 model 을 update한다.
- 1~5를 epoch만큼 반복한다.
이렇게 했을 때 매번 class에 대한 labeling이 달라지기 때문에, 각 specific한 class들을 학습하는 것이 아니라 학습하는 방법을 배우는 효과를 보이게 됩니다. 예를 들어, Figure 2에서는 car를 class 1에 labeling 했지만, 다른 epoch일 때는 class 2가 될수도 있고 class 3이 될 수도 있습니다. 즉, model이 car 자체를 학습하는 것이 아닌 car를 구별할 줄 아는 능력을 키우게 되는 것이죠. 이렇게 됐을 때 아예 새로운 task가 들어와도 어느 정도는 잘 구별할 수 있게 됩니다. Generalization 관점에서 이득이 되는거죠.
여담으로, 요즘 LLM/LMM을 학습시킬 때 대부분 few-shot 또는 zero-shot learning으로 학습시킵니다. (zero-shot learning은 다음에 기회가 될 때 따로 posting하겠습니다.) 사실, LLM/LMM의 장점은 어떤 특정 상황에서만 잘 하는 것이 아닌 다양한 상황에서도 좋은 performance를 내는 것인데, 이럴 때 few-shot 또는 zero-shot learning으로, 즉 상황을 구별하는 법을 학습시키는 것이 합리적입니다. 기회가 된다면 LLM/LMM에 대한 posting을 할 때 좀 더 detail하게 설명하도록 하겠습니다.
*추후 연재
최대한 자세하게 posting을 할려다보니까 너무 길어졌네요… 원래는 한 post내에 모든 정보를 담으려 했으나, 적다보니 설명할 부분들이 생각보다 많고 다룰 내용도 너무 많아, 더 이상 길어지면 안될 것 같습니다… 그래서 우선은 여기서 wrap-up하고, 추후에 시리즈 형식으로 meta learning approaches, methods, 의의 등에 대해 posting을 이어가도록 하겠습니다!! 읽어주셔서 감사합니다!! ![]()