Sharp-MAML: Sharpness-Aware Model-Agnostic Meta Learning
1. What is SAM?
SAM (Sharpness Aware Minimization) 은 ICLR 2021에 publish된 논문으로, Google Research에서 generalization 연구에 대해 새로운 관점을 열어준 논문입니다. SAM의 핵심 목표는 다음 두가지 입니다.
- Improves Model Generalization via Finding Flat Minima
- Provides Robustness to Label Noise
여기서 flat minima를 찾는다는 것은 어떤 의미일까요? SAM 알고리즘으로 넘어가기 전에, flat minima가 의미하는 바에 대해서 짧게 짚고 넘어가겠습니다.
1.1 Flat Minima
Flat minima는 기본적으로 Deep Learning에서 generalization을 얘기할 때 나오는 개념 중 하나입니다. Loss Landscape 관점으로 볼 때, 만약 loss의 minima 지역이 flat하다면 비교적 좋은 generalization을 보이고, loss의 minima 지역이 sharp하다면 specific한 task에서 좋은 성능을 보인다고 볼 수 있습니다. 아래 그림[1]을 보시면 좀 더 직관적으로 이해하실 수 있습니다.
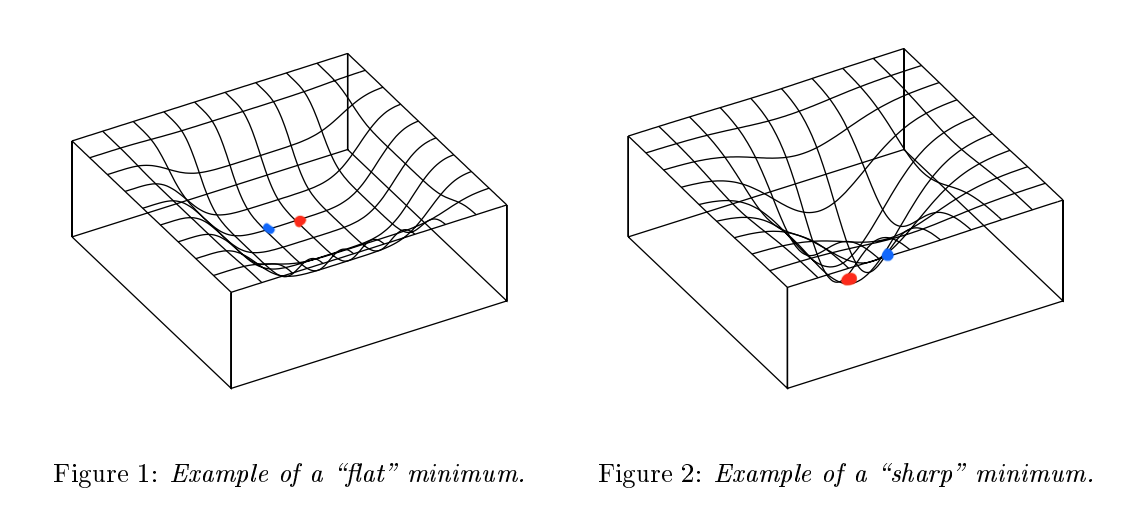 |
그림 [1]: Example of Flat minimum & Sharp Minimum
그림[1]에서 Figure 1을 보시면 loss landscape이 깊진 않지만 flat하게 돼있고 Figure 2를 보시면 loss landscape이 깊지만 narrow하게 돼있습니다. Figure 1의 minima 지점(
그러나 Figure 2는 landscape이 가파르기 때문에 minima에서 조금만 벗어나더라도 loss 값 차이는 크게 날 것입니다. 즉, Figure 1은 빨간색 점과 파란색 점 위치에서의 loss 차이가 작은 반면 Figure 2는 빨간색 점과 파란색 점 위치에서의 loss 차이가 크다고 볼 수 있습니다. Deep Learning은 학습이 언제나 optimal한 지점을 찾아간다는 보장이 없기 때문에 loss landscape을 flat하게 만들어 줬을 때 generalization 관점에서 더 유리하다고 볼 수 있습니다.
(다만… 정말로 flatness가 generalization에 큰 영향을 주냐에 대해 다른 관점이 있기도 합니다; Li, Hao, et al. “Visualizing the loss landscape of neural nets.” Advances in neural information processing systems 31 (2018). 논문 )
1.2 SAM Algorithm
그렇다면 loss landscape을 어떻게 flat하게 만들어 줄 수 있을까요? SAM algorithm은 다음 4가지 step을 통해 flat minima를 찾습니다. (수식을 통한 proof는 생략하겠습니다.)
- Loss 구하기: \(\mathcal{L}_\mathcal{B}\)
- 구한 Loss의 ”+” gradient 방향으로 이동: \(\hat{\epsilon}(w)\rightarrow\) \(w_{adv}=w_t+\hat{\epsilon}(w)\)
(= 제일 높은 Loss로 이동) - 이동한 위치에서 gradient 계산: \(g =\nabla\mathcal{L}_\mathcal{B}(w)|_{w+\hat{\epsilon}(w)}\)
- 기존 위치에서 weight update 진행: \(w_t=w_t-\eta g\)
*2와 3의 경우 논문에 proof가 아주 자세히 나와있습니다. \(\epsilon\)을 포함한 연산 시, Taylor Expansion을 통해 approximate합니다. 현재는 SAM논문 리뷰는 아니기 때문에… 관심있으신 분들은 논문을 직접 한번 보시면 좋을 것 같습니다. 다음에 기회가 있으면 리뷰하도록 하겠습니다. (https://arxiv.org/abs/2010.01412)
SAM의 핵심은 minmax optimization 기반의 알고리즘으로 생각하시면 됩니다. 보통 학습 시 gradient update할 때 \(w = w - \nabla_w{L(w)}\) 형태로 진행합니다. Loss에 대해 계산한 gradient의 반대 방향으로 update을 하는 것이죠. 하지만 SAM 알고리즘에서는 우선 gradient의 정방향으로 이동합니다. 이에 대한 의미는 제일 낮은 loss를 찾는 것을 포기하더라도 제일 높은 loss들을 낮추는 방향을 고려하여 gradient update을 하겠다는 것입니다. (그림[2] 참조)
조금 더 쉽고 직관적으로 설명하자면 제일 높은 loss를 꾹꾹 눌러주면서 update을 진행하 겠다는 것입니다. 낮은 loss를 찾는 것이 아닌 높은 loss들을 낮춰줌으로써 loss landscape을 전반적으로 flat하게 만들어주겠다는 것입니다.
 |
그림 [2]: SAM Algorithm
SAM은 하나의 model 알고리즘이 아닌 optimization algorithm이기 때문에 다양한 model에 적용할 수 있습니다. (optimizer처럼 활용 가능)
2. What is MAML?
MAML(Model-Agnostic Meta-Learning)은 2017년에 Chelsea Finn (당시 박사과정)교수가 쓴 논문으로 Meta-Learning의 시작을 알린 논문 중 하나입니다. 너무 유명한 논문이여서 많은 사람들이 알고 있겠지만, Meta-Learning이 무엇인지, 또한 MAML이 어떤 알고리즘인지 간단한게 설명하겠습니다.
2.1 Meta-Learning
그 전에, 여기서 Meta-Learning은 무엇일까요? Meta-Learning은 few-shot learning 분야 중 한가지입니다. Label 중심(supervised learning)으로 학습하는 것이 아닌 여러가지 task 중심으로 학습하여, 아예 새로운 task가 들어오더라도 잘 분류/예측할 수 있는 학습 방법입니다. 즉, 새로운 task를 빠르게 adapt하는 방법을 학습하는 것입니다. (task: datasets으로부터 N개 종류의 data를 K개씩만큼 뽑은 sample → N-way K-shot)
Meta-Learning의 학습 방법을 보통 다음 3가지로 나눕니다.
- model-based
 task의 model을 중심으로 학습
task의 model을 중심으로 학습 - metric-based (non-parametric) task parameter상 distance를 중심으로 학습
- gradient-based (parametric) task parameter의 gradient를 중심으로 학습
여담으로, 각 방법들은 사용되는 application에 따라 달라집니다.
Meta-Learning 역시 meta-training 및 meta-validation/test 과정이 있습니다.
2.2 MAML
MAML은 위에서 분류한 학습 방법 중 gradient-based meta-learning에 속합니다. MAML은 현재까지 meta-learning과 관련된 대부분의 논문에 reference되고 있는데, 굉장히 단순하고 활용하기 편하기 때문입니다. MAML 이름에도 나와있듯이 어떤 모델이든(Model-Agnostic하게) 활용할 수 있고 다양한 task들에 대해 빠르게 적응(fast adaptation)할 수 있기 때문입니다. MAML을 이루고 있는 핵심 process는 다음 두가지 입니다.
- Initialized $\theta$ 에서 fine-tuning을 통해 task들을 loss 계산 (Inner-Loop)
- 구한 loss로 $\theta$ gradient update (Outer-Loop)
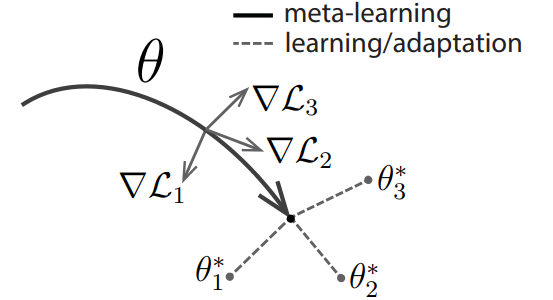
결국 MAML의 최종 목표는 어느 task도 잘 cover할 수 있는 위치로 initialized $\theta$를 보내는 것입니다. 그렇게 하기 위해 위에서 말한 두 과정을 거치는데, 다음 그림[3]과 notation을 통해 자세히 설명하겠습니다.
 |
 |
그림[3]: Diagram and Algorithm of MAML
Notation :
$\mathcal{T_i} = (\mathcal{S_i}, \mathcal{Q_i})$ : (Support, Query) datasets
$\theta$ : Initialized parameter
$\theta^\prime$ or $\phi$ : fine-tuned parameter
$\nabla \mathcal{L_i}$ : gradient of loss from fine-tuned parameter
*(다른 블로그 및 논문들과 notation이 상이할 수 있습니다.)
위에서 언급했듯 MAML을 이해하려면 두 가지 process: Inner & Outer Loop를 이해해야 합니다.
- Inner-Loop & Outer-Loop
우선 Inner-Loop입니다. Inner-Loop는 fine-tuning을 통해 해당 task의 최적의 point를 찾아가는 과정입니다. 이 과정을 수식으로 표현하면 $\theta^{\prime} = \theta - \alpha \nabla_{\theta} \mathcal{L}(\theta) $입니다. (그림[3]의 오른쪽의 6번 과정과 동일) 이 과정은 Stochastic Gradient Descent 와 동일합니다. 즉, SGD을 통해 빠르게 해당 task의 최적의 point를 찾는 과정입니다. MAML 논문에서는 이 과정을 5step 진행합니다. 수식적으로 볼 때 2step 이상부터는 위 SGD 식에서 (당연하지만) $\theta$ → $\theta^{\prime}$ 으로 바뀝니다.
Inner-Loop의 세부과정은 다음과 같습니다.
- Sample $\mathcal{T_i}$: ($\mathcal{S_i}$, $\mathcal{Q_i}$) from distribution $\mathcal{p(T)}$
- Iterate $\theta^{\prime} ← \theta - \alpha \nabla_{\theta} \mathcal{L}(\theta)$ with the $\mathcal{S_i}$ N times (= fine-tuning)
- Calculate the $\mathcal{L}(\theta^{\prime})$ using the $\mathcal{Q_i}$
위 세부과정을 쉽게 설명하면, support set으로 fine tuning을 하고 fine tuning을 한 위치에서 query set으로 성능확인, 즉 loss를 구합니다.
그 다음은 Outer-Loop입니다. Outer-Loop는 Inner-Loop에서 구한 loss들의 평균으로 $\theta$ 를 update하는 과정입니다. 여기서의 핵심은 fine-tuning한 지점에서 update을 하는 것이 아닌 fine-tuning을 시작한 지점: $\theta$에서 update을 한다는 것입니다. 이 과정을 수식으로 표현하면 $\theta = \theta - \beta \nabla_{\theta} \sum \mathcal{L}(\theta^{\prime}) $ 입니다. (그림[3]의 오른쪽의 8번 과정과 동일) 이 수식에 대한 의미는 다음과 같이 생각해볼 수 있습니다.
- $\mathcal{S_i}$을 활용하여 해당 task에 대한 정보를 일부 제공하고, 모델을 학습시킵니다. (=Fine-tuning)
- Fine-tuning 후, $\mathcal{Q_i}$을 활용하여 해당 Task에 대한 성능을 평가하고 Loss를 구합니다. (= Loss를 구한다)
- 2.에서 구한 Loss의 Gradient를 통해 $\theta$가 학습할 방향성을 확보합니다.
- $n$개의 task에 대한 loss의 gradient를 평균을 기준으로 update 한다. ($i = 1,2,…,n$)
$\mathcal{Q_i}$으로 구한 loss의 gradient (gradient vector)를 앞으로 update를 해야하는 방향성을 알려주는 거라고 생각할 수 있습니다. 처음부터 unseen-task (여기서는 $\mathcal{Q_i}$)를 training하는 것은 어렵고 비효율적이니, $\mathcal{S_i}$으로 어느정도 adapt한 후, unseen task를 통해서 나온 gradient로 training 하는 것입니다. 하나하나의 task 또는 data들을 학습하는 supervised learning과 달리 optimal한 지점으로 가는 방법을 학습 한다고 볼 수 있습니다. 이렇게 됐을 때, 특정 data에 대해 학습을 하는것이 아니기 때문에 overfitting이 잘 일어나지 않을 뿐 더러, unseen-task도 빠르게 adapt할 수 있어 generalization에 강점이 있습니다.
다만, 이렇게 됐을 때, Inner-Loop 때 미분, Outer-Loop 때 미분, 총 2번 미분(hessian)을 하기 때문에 computational cost가 약간 큰 단점이 있습니다.
앞으로는
3. Sharp-MAML?
Sharp-MAML논문은 위에서 설명한 SAM과 MAML을 합친거라고 보시면 됩니다.
3.1 Problem Formulation & Algorithm
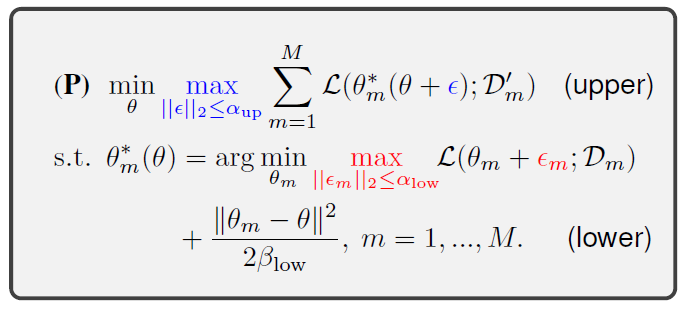
- Fine-Tuning 때만 적용: $\alpha_{up} = 0$ & $\alpha_{low} > 0$
- Meta-update 때만 적용: $\alpha_{up} > 0$ & $\alpha_{low} = 0$
- Both 적용: $\alpha_{up} > 0$ & $\alpha_{low} > 0$
그림[4]: Problem formulation of Sharp-MAML
그림[4]에서 오른쪽을 보시면 MAML에 SAM을 어떻게 적용했는지 알 수 있는데, fine-tuning, meta-update, Both 이렇게 총 3가지 방법으로 적용했습니다.
먼저 lower 부분을 보겠습니다. 논문의 저자는 fine-tuning할 때 한 step update할 때마다 주변부에 perturbation을 줘서 높은 loss를 찾고 그 loss를 기준으로 낮추는 방향으로 진행합니다. 논문에 나온 수식은 다음과 같습니다.
들어가기 전!!
- For each task m…
- perturbation: $\epsilon_{m}(\theta) = \alpha_{low} \nabla \mathcal{L}(\theta) / ||{\nabla \mathcal{L}(\theta)}||_{2}$
- maximum point (=maximum loss): $\theta + \underset{||\epsilon_m||_{2} \leq \alpha_{low}}{\max} \epsilon_{m}(\theta)$
- gradient descent: $\tilde{\theta^1} = BGD(\theta, 0, \epsilon_m) = \theta -\beta_{low}\nabla \mathcal{L}(\theta + \epsilon_{m}(\theta))$
- regularizer term: $\frac{|| \theta_m - \theta ||}{\beta_{low}}$
그 다음은 upper 부분입니다. 여기서도 perturbation을 줘서 해당 범위 내에서 가장 높은 loss를 찾고 그 loss를 낮추는 방향으로 진행합니다. 다른 점은 perturbation을 줄 때 fine-tuning때 계산했던 gradient를 활용합니다. 논문에 나온 수식은 다음과 같습니다.
- (meta) perturbation: \(\epsilon(\theta) = \alpha_{up} \nabla \mathcal{h} / \|\mathcal{h}\|_2\) (→ \(\nabla \mathcal{h} = \nabla_{\theta} \sum_{m=1}^{M}\mathcal{L}(\tilde{\theta^1})\))
- maximum point: $\theta + \underset{||\epsilon_m||_{2} \leq \alpha_{low}}{\max} \epsilon_{m}(\theta) + \epsilon(\theta)$
- gradient descent: $\tilde{\theta^2} = BGD(\theta, \epsilon, \epsilon_m) = \theta + \epsilon - \beta_{low} \nabla \mathcal{L}(\theta + \epsilon + \epsilon_m)$
- meta-update: $\theta \leftarrow \theta - \beta_{up} \sum_{m=1}^M \nabla_{\theta}\mathcal{L}(\tilde{\theta^2}) $
위 과정을 Pseudo-Code로 보이면 그림[5]와 같습니다.

그림[5]: Pseudo-Code for Sharp-MAML
3.2 Results
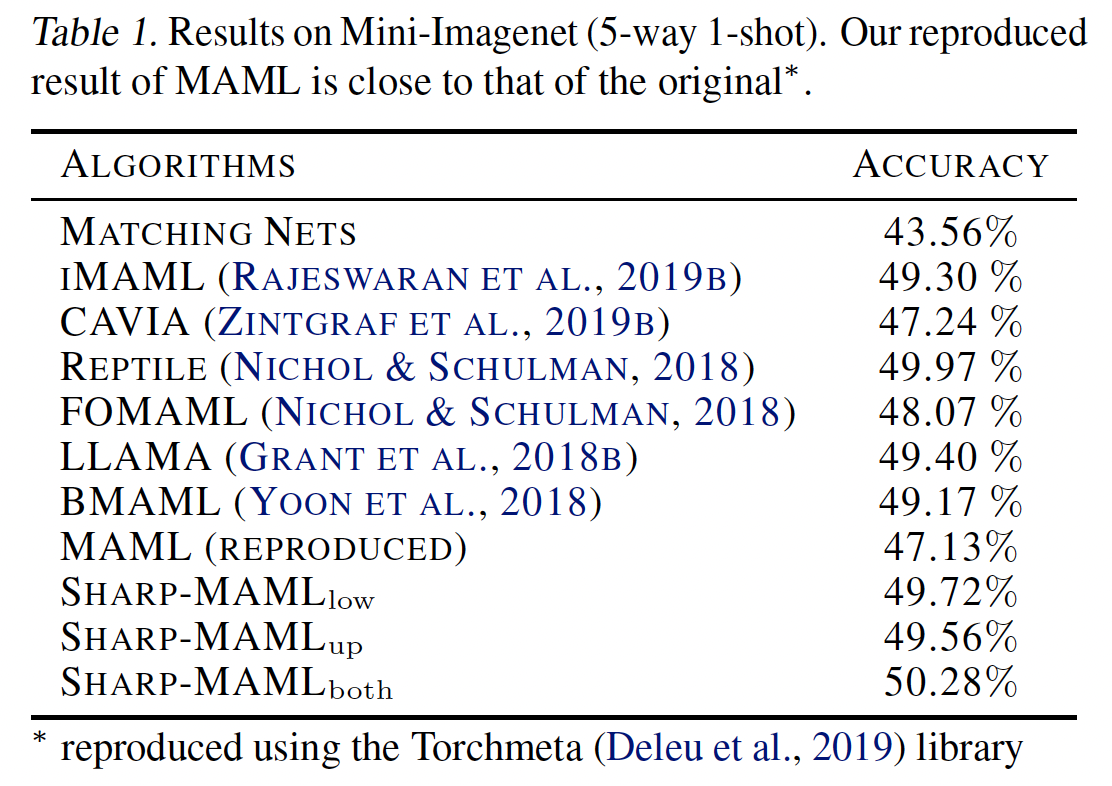
결과는 다음과 같습니다.
 |
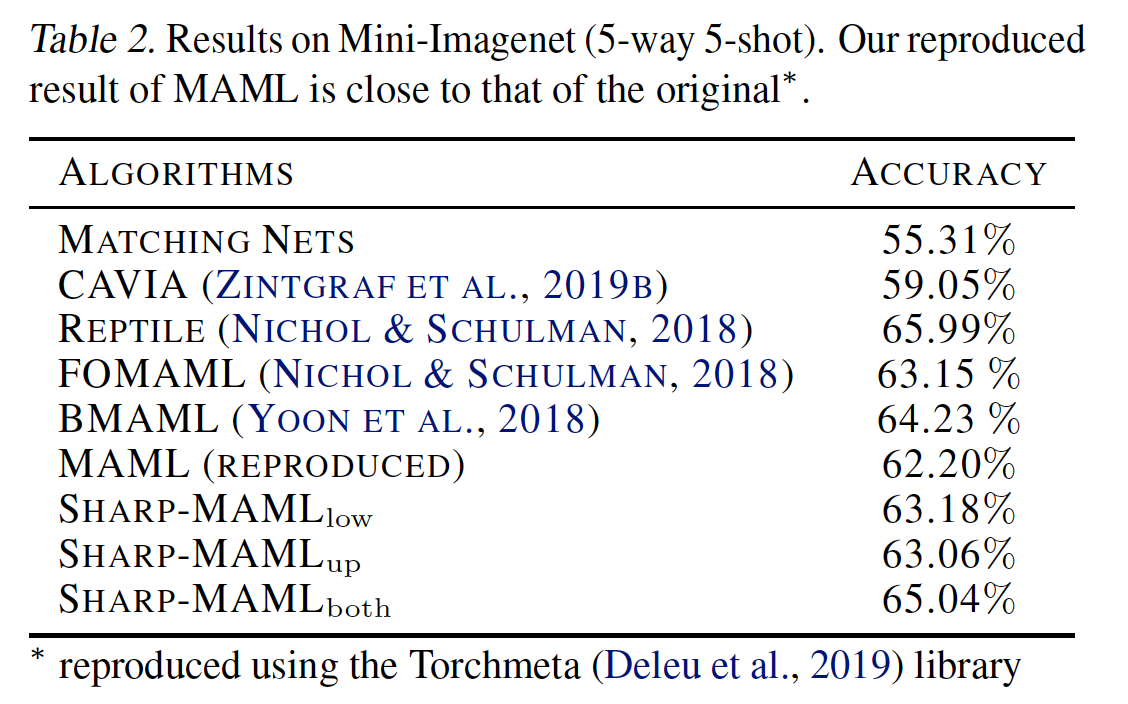 |
그림[6]: Results of Sharp-MAML
다소 아쉬웠습니다. 약 2~3%정도의 gain이 있는데 요즘 나오는 meta-learning 계열의 논문들에 비해 아주 큰 gain은 아닙니다. 실은 제가 이 논문을 처음 읽었을 때(작년 2022년 5월쯤…) 공식 published 논문에 결과는 5way-1shot 기준 60%정도가 나왔었는데 최근에 다시 찾아보니 50%로 바뀌어있었습니다. Novelty적인 면에서는 분명 contribution이 있으나 결과가 아주 뛰어나진 않기 때문에 gain이 많았으면 좀 더 훌륭한 논문이 되지 않았을까 하는 생각이 듭니다. 또한 generalization을 좀 더 강조하고 싶었다면 cross domain adaption의 결과도 같이 있었으면 어땠을까 생각됩니다.
마지막으로 Sharp-MAML의 loss landscape과 함께 어떤 의미가 있는지 간략히 살펴보겠습니다. (주관적인 생각도 포함돼있습니다.)
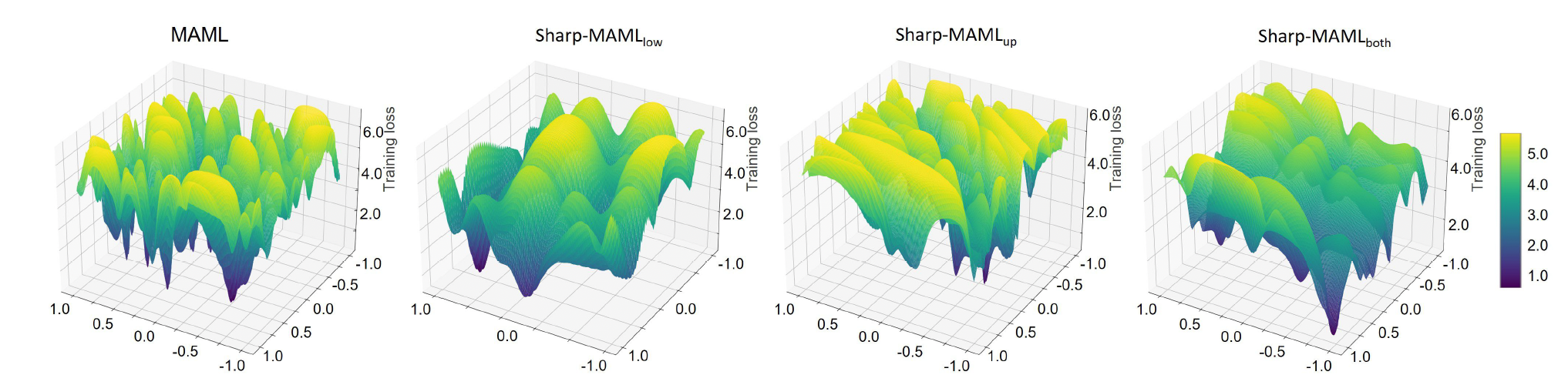
그림[7]: Loss Landscape of Sharp-MAML
그림[7]을 보면 기존 MAML보다 나름 flat해진 것을 볼 수 있습니다. MAML논문을 보면 generalization에 강점이 있다고 했는데 과연 MAML도 flat할까?라는 궁금증이 있었습니다. 하지만 loss landscape상으로 아주 flat하진 않았습니다. 그렇다면 여기서 MAML의 loss landscape이 flat해졌을 때 generalization이 더 상승할까?를 생각해볼 수 있고, Sharp-MAML이 그 결과를 보여줬습니다. 곰곰히 생각을 해보면, loss landscape이 flat할 때 여러 task들이 fine-tuning 또는 meta-update 때 local minima에 빠질 가능성도 줄어들기 때문에 generalization이 상승할 가능성이 높아진다고 생각해볼 수 있습니다.
4. Conclusion
Meta-Learning을 공부하면서 Flatness에 관심을 가지던 찰나에 Sharp-MAML논문이 나왔습니다. MAML을 generalization 관점에서 보면서 flatness로 풀려는 모습이 인상적이였습니다. 다만, gradient-based이기 때문에 novelty가 아무리 좋아도 아직 black-box의 한계(?)를 넘기에는 부족하고 많은 연구가 필요한 것 같습니다. 이 논문의 novelty를 좀 더 확인하고 싶으신 분들은 논문에서 theoratical analysis 부분 또는 appendix를 정독해보면 좋을 것 같습니다.
5. Reference
- Abbas, Momin, et al. “Sharp-MAML: Sharpness-Aware Model-Agnostic Meta Learning.” International Conference on Machine Learning. PMLR, 2022. (논문)
- Finn, Chelsea, Pieter Abbeel, and Sergey Levine. “Model-agnostic meta-learning for fast adaptation of deep networks.” International conference on machine learning. PMLR, 2017. (논문)
- Foret, Pierre, et al. “Sharpness-aware minimization for efficiently improving generalization.” arXiv preprint arXiv:2010.01412 (2020). (논문)
- Li, Hao, et al. “Visualizing the loss landscape of neural nets.” Advances in neural information processing systems 31 (2018). (논문)