Nevertheless, I believe the concept of Meta Learning and its effectiveness are still important. In particular, when training foundation models such as
Therefore, I think it is important to know the concept of Meta Learning, or in a smaller category, Few-Shot Learning. You don't need to know all the specific related algorithms, but I thought that knowing how to define problems and set up training settings when utilizing Meta Learning would allow for more diverse approaches, so I decided to cover this.
0. What is Meta Learning?
When explaining Meta Learning, many people describe it as “Learn to Learn.” Put simply, you can think of it as the way humans learn. As humans live, they accumulate various experiences and acquire new knowledge based on them. At this time, humans acquire new knowledge by combining existing knowledge with new experiences Even if they aren’t taught everything from A to Z, they can infer based on the knowledge they already possess (of course, completely new things are exceptions). For example, even if someone cannot distinguish between an apple and a dog at first, through a few experiences, they grasp the characteristics of apples and dogs, and based on this, they become able to distinguish new apples or dogs. And later, even if they see an animal similar to a dog or a fruit similar to an apple, they become able to distinguish them. Like this, humans have the ability to learn through ‘experience’, and Meta Learning is the application of this human learning ability to deep learning training methods.
1. Few-Shot Learning
Then, let’s try applying this process to AI model training methods.
First, let’s think about conventional deep learning. Existing deep learning requires training numerous images for each class, as shown in Figure 1 below. However, training this way causes problems such as overfitting, and from a generalization perspective, it is difficult to find methods other than inputting more diverse data. However, since data is always limited, gathering more data, and more diverse data, is difficult and inefficient. Then, what should we do to train deep learning efficiently like humans? One of the concepts introduced in this situation is “Few-Shot Learning”.
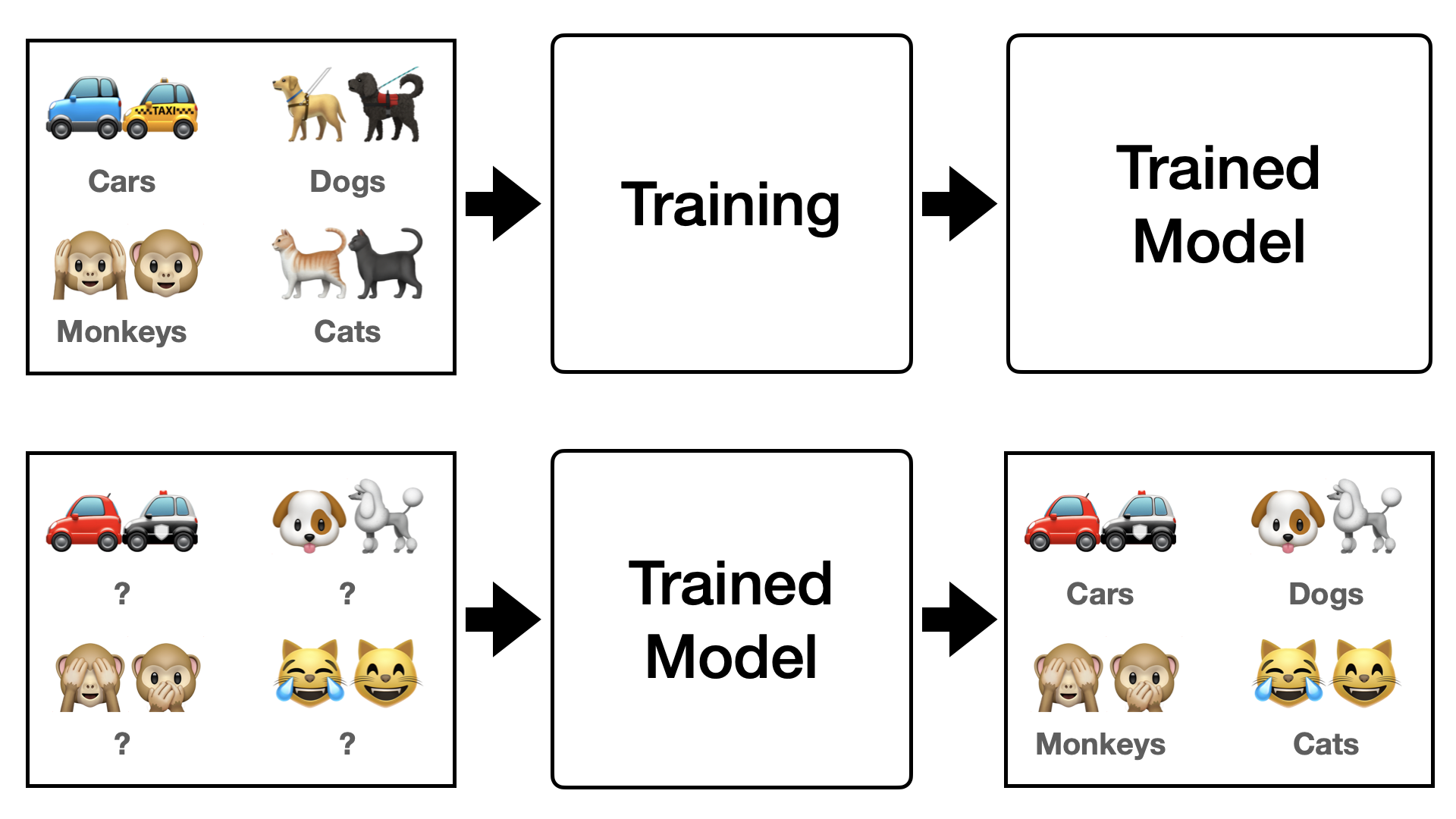
To express Few-shot learning simply, it is learning by seeing only a few data. In other words, it is a method of training by showing only a few data every epoch. Here, you must not be confused; it does not mean training with only a few data in total, but extracting a few data from the entire data to proceed with training. Therefore, the setting method is also slightly different from conventional deep learning methods. To understand the Few-Shot setting, you need to know the concepts of $N$-ways $K$-shots, as well as the Support Set ($S$) and Query Set ($Q$).
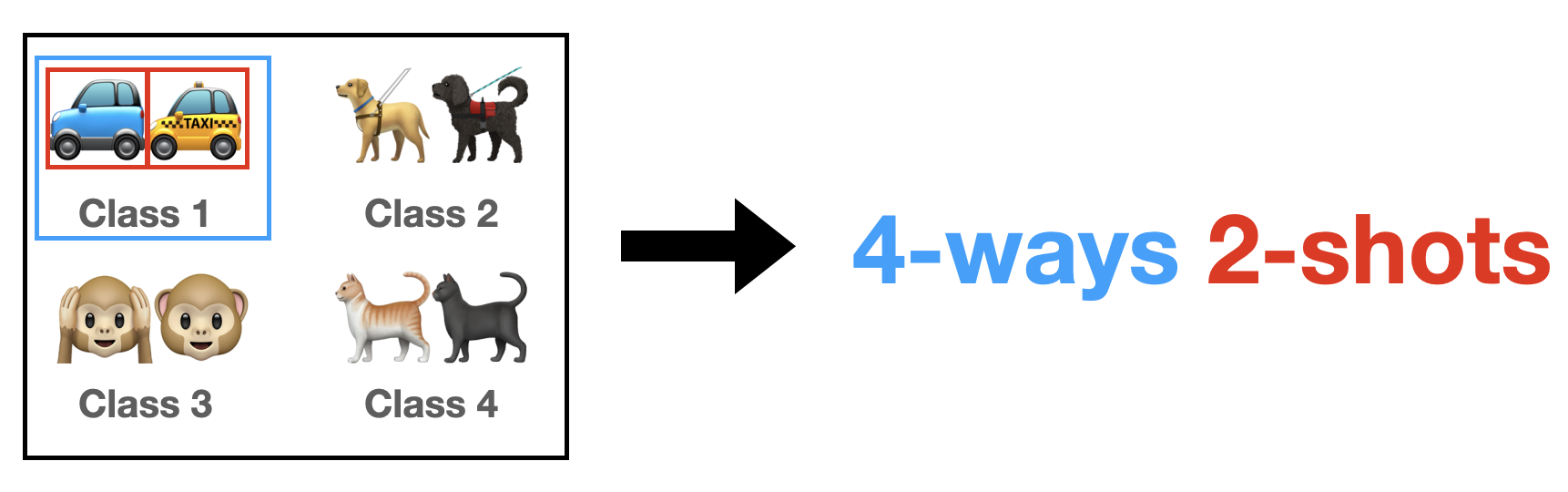
1.1 $N$-Ways $K$-Shots
Here, $N$ means the number of classes to extract from among the classes of the entire datasets (Figure 2). And here, $K$ means the number of images to extract per class. For example, let’s assume the total classes of a certain dataset is 100. And if we say the experiment setting is 5-ways 1-shot, every epoch, we randomly select 5 classes out of 100 classes, and extract 1 image for each class.
1.2 Support Set ($S$) and Query Set ($Q$)
First, before explaining, you must think of $S$ and $Q$ as a bundle. In the AI community, this bundle is expressed as an episode or task. Going further, few-shot learning is sometimes expressed as episodic learning. When training, we pick episodes/tasks corresponding to the batch size every epoch.
Here, $S$ are the data that directly participate in training according to the method, and $Q$ are the data used to evaluate how well it was trained after training. Those encountering few-shot learning for the first time might find this setting a bit confusing. So, I will explain through Figure 3 below.
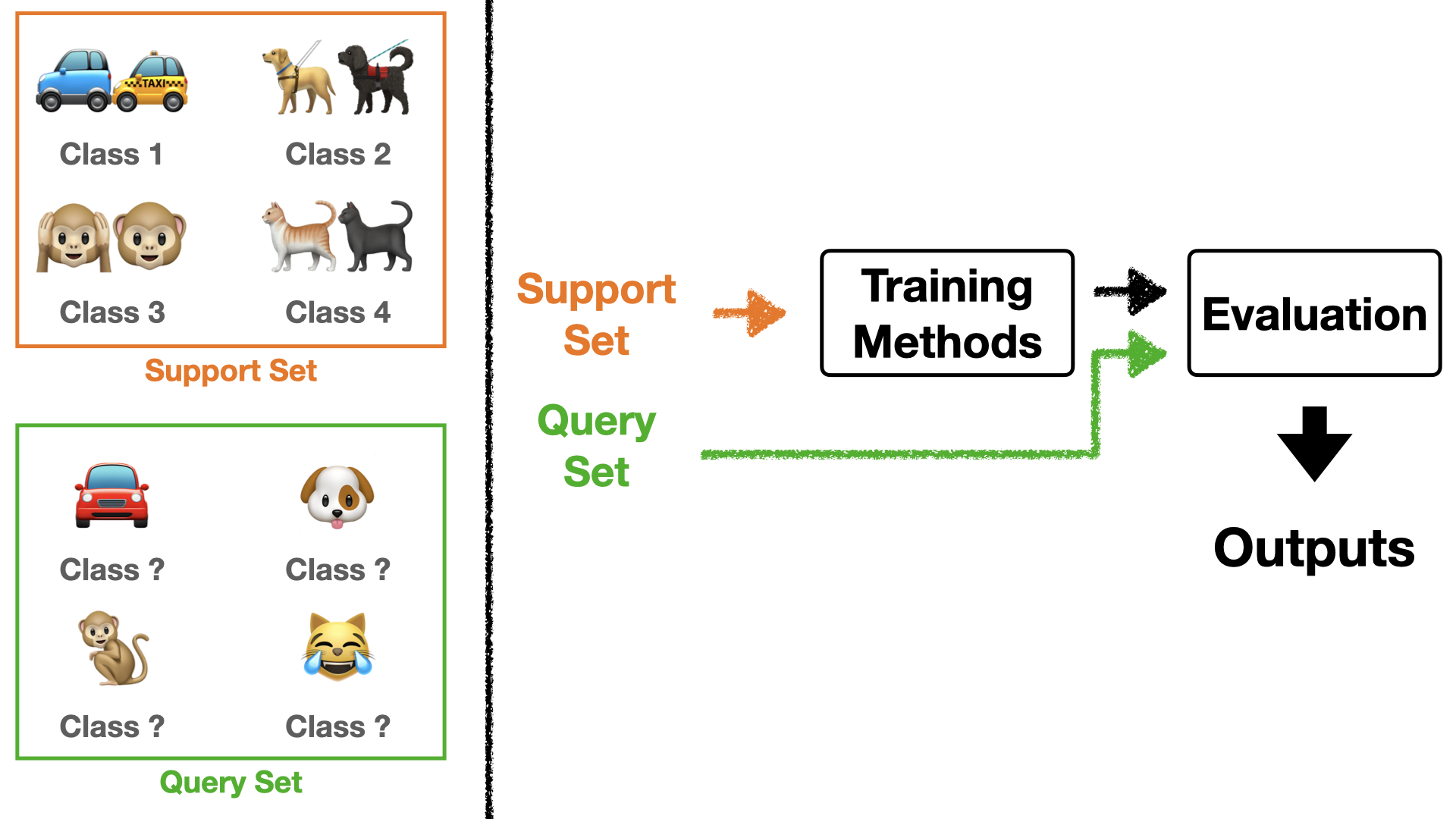
If you look at Figure 3, examples for $S$ and $Q$ are shown on the left. $S$ participates in training while knowing what class it is. In other words, we train the model with $S$ like supervised learning. So $S$ follows $N$-ways $K$-shots. And $Q$ is put into the trained model without knowing what class it is, and the result is utilized as an evaluation metric.
One important point here is that while $Q$ follows $N$-ways, it does not follow $K$-shots. That is, the number of classes is fixed due to $S$, but the number of images per class is not fixed. It means we don’t necessarily have to pick $K$ images per class. Usually, the query set picks 15 data points per class.
Additionally, we usually express $S$ as the seen task and $Q$ as the unseen task. Ultimately, the reason for doing few-shot learning is to achieve good performance on unseen tasks, so updates are proceeded with $Q$.
1.3 Wrap-up
To summarize Few-shot learning, it is as follows:
- Sample a task(= [$S$, $Q$]) according to $N$-ways $K$-shots.
- Train with $S$ according to the method.
- Evaluate whether it was trained well with $Q$.
- Extract the final loss from the result in 3.
- Update the model with the loss from 4.
- Repeat 1~5 for the number of epochs.
When done this way, since the labeling for classes changes every time, it shows the effect of learning how to learn rather than learning each specific class. For example, in Figure 2, ‘car’ was labeled as class 1, but in another epoch, it could be class 2 or class 3. In other words, the model develops the ability to distinguish cars rather than learning the car itself. When this happens, even if a completely new task comes in, it becomes able to distinguish it to some extent. It becomes beneficial from a Generalization perspective.
As a side note, when training LLM/LMM these days, most are trained with few-shot or zero-shot learning. (I will post about zero-shot learning separately when I have a chance next time.) In fact, the strength of LLM/LMM is not just doing well in a specific situation but producing good performance in various situations. In this case, it is reasonable to train them with few-shot or zero-shot learning, that is, teaching them how to distinguish situations. If I have the chance, I will explain in more detail when posting about LLM/LMM.
*Future Series
Trying to post as detailed as possible made it too long. Originally, I intended to put all information in one post, but as I wrote, there were more parts to explain and too much content to cover than I thought, so I think it shouldn’t get any longer. So, I will wrap up here for now, and continue posting about meta learning approaches, methods, significance, etc., in a series format later. Thank you for reading.