However... since so many papers have been published since 2017, it is impossible to cover all of them, so I will organize the summary mainly around key papers and papers that I found interesting to read. And in the next post, I will take time to briefly review papers focused on advanced methods.
2. Meta Learning Approaches
Actually, the reason I explained few-shot learning in the previous post was to explain meta-learning. You can understand meta-learning as applying various approaches utilizing the concept of Few-shot learning. Without further ado, let’s see what concepts exist in meta-learning.
Meta-learning can basically be classified into the following 3 broad categories:
- Optimization-based Approach
- Metric-based Approach
- Model-based Approach
I will explain the key approaches of important papers for each category. However, I will skip the model-based approach here. Since model-based approaches are usually used a lot in RL, I will post about them separately next time if I have the chance.
It would be good to check how $S$ and $Q$ are utilized for training while reading.
2.1 Optimization-based Meta Learning
Optimization-based meta-learning is a method of learning centered on gradients. Accordingly, the very first paper mentioned is Model-Agnostic Meta-Learning (MAML), which came out in 2017. It is essentially the paper that popularized the concept of “Meta Learning”. Then let’s examine what kind of paper MAML is.
2.1.1 MAML
The final goal of MAML is to train the model parameter $\theta$ to a position where fast adaptation/finetuning (hereinafter FT) is possible. The keyword to notice here is “FT”. The core mechanism of MAML is ultimately “It would be efficient if we can reach specific tasks through a few steps of parameter updates!”. Let me explain with an example. If a person has a job that requires traveling all over the country (Korea), it would be more efficient to live in Daejeon (central region) than to live in Busan, Gangneung, or Incheon. Like this, moving $\theta$ to a position where it can quickly reach tasks is better for achieving good performance on various tasks than learning every task individually.
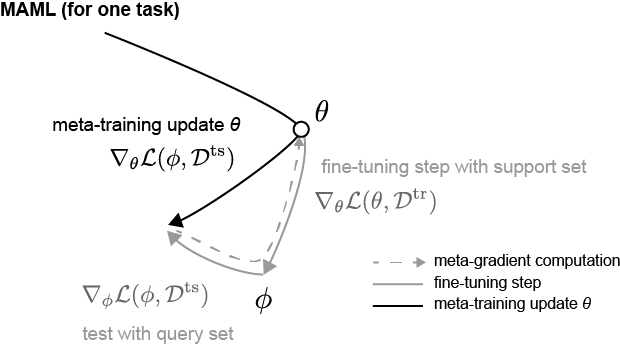
While the paragraph above explained it in words, let’s look at it mathematically this time. Before diving in, MAML is divided into an inner-loop and an outer-loop to train one epoch. The inner-loop is the FT mentioned above, and the outer-loop is the model update$^*$. The MAML algorithm is as shown in Figure 1.
$^*$ Usually, this process is also called bi-level optimization.
 |
 |
And explaining the pseudo-code above in detail:
- Initialize model parameter $\theta$ (line 1)
- Sample task $\mathcal{T}$ =($S$,$\mathcal{Q}$ ) ; $\mathcal{T} \sim p(\mathcal{T})$ along with the number of batches (line 3)
- Inner-Loop updates with $n$ steps (line 4-7):
- Repeat SGD update: $\phi = \theta - \alpha\nabla_\theta \mathcal{L}(S;\theta)$
- From $n \geq 2$, it changes from $\theta$ → $\phi$; i.e., update in the form of $\phi = \phi - \alpha \nabla_\phi \mathcal{L}(\mathcal{S}; \phi)$
- Outer-Loop (line 8):
- With fine-tuned model $\phi$, evaluate with $\mathcal{Q}$ and update
- $\Rightarrow$ $\theta \leftarrow \theta - \frac{1}{N}\sum_{i=1}^N \nabla_\theta \mathcal{L}_i(\mathcal{Q};\phi) $
- Repeat 2-4 (line 2-9)
The part to keep an eye on here is the derivative (meta-gradient) during the outer loop. If you look, when performing the outer loop update, it differentiates not with $\phi$ but with $\theta$ for the loss value resulting from the fine-tuned parameter $\phi$ and $Q$. The related formula expands as follows by the chain rule.
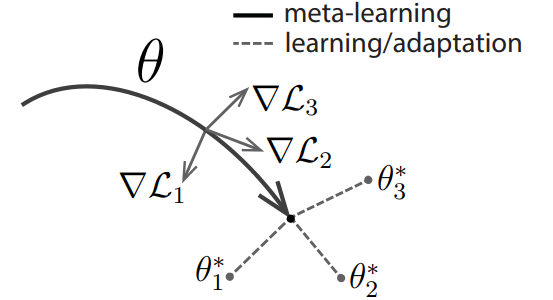
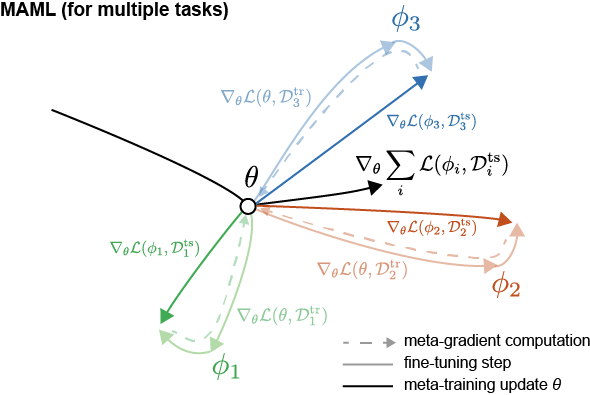
\[\begin{aligned} \nabla_\theta \mathcal{L}(\mathcal{Q};\phi) &= \frac{\partial }{\partial \theta}\mathcal{L}(\mathcal{Q};\phi) \\ &= \frac{\partial \mathcal{L}(\mathcal{Q};\phi)}{\partial \phi} \frac{\partial \phi}{\partial \theta} \\ &= \nabla_\phi \mathcal{L}(\mathcal{Q};\phi)\nabla_\theta \phi \\ &=\nabla_\phi \mathcal{L}(\mathcal{Q};\phi)\nabla_\theta (\theta - \alpha \nabla_\theta \mathcal{L}(\mathcal{S};\theta)) \\ &= \nabla_\phi \mathcal{L}(\mathcal{Q};\phi)(I - \alpha \nabla^2_\theta \mathcal{L}(\mathcal{S};\theta)) \\ \end{aligned}\]The purpose of this formula is ultimately to update $\theta$ towards a lower loss, but to update it in a direction that lowers the loss $\mathcal{L}(\mathcal{Q};\phi)$ at the FT’d $\phi$. This might feel ambiguous, but looking at Figure 2 might help you understand the direction of the update to some extent. (Reference: Boyang Zhao’s Blog, the notation is slightly different, but you can just view loss as loss.)
 |
 |
2.1.2 FOMAML, Reptile
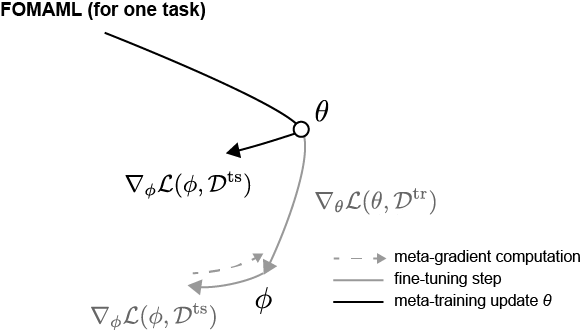
In the case of MAML, Hessian matrix multiplication ($=\nabla_\theta^2 \mathcal{L}(\mathcal{S};\phi)$) is included, so there is a penalty from a computational cost perspective. So, methods were proposed to reduce computational cost while maintaining performance to some extent.
One of them is FOMAML (First-Order MAML). FOMAML was experimentally verified in the MAML paper, showing that it maintains performance to some extent even if training proceeds while ignoring the Hessian matrix. In other words, it assumes $\nabla_\theta^2 \mathcal{L}(\mathcal{S};\phi) = 0$. This is well shown in Figure 3; it applies the “direction of the gradient” that lowers the loss $\mathcal{L}(\mathcal{Q};\phi)$ at the finetuned $\phi$ to $\theta$. The paper explains that this mechanism is possible because the Hessian value converges to 0 while passing through ReLU. Thinking from a Loss landscape perspective, the “direction lowering the loss” is similar. That is, it implicitly contains the assumption that the final updated $\theta$ position in MAML and the $\theta$ position in FOMAML are in a similar loss landscape.
Next is the Reptile paper. The Reptile paper was published by OpenAI in 2018, and you can think of it as a variant of FOMAML. The characteristic of Reptile is that $S$ and $Q$ do not exist separately. It trains in few-shot, but it picks multiple tasks and trains the tasks selected through sampling. Then, it proceeds with the update using the difference between the initial model parameter $\theta$ and the fine-tuned model parameter $\phi$ as the gradient. Figure 4 below is a picture of the Reptile algorithm and the update direction.
 |
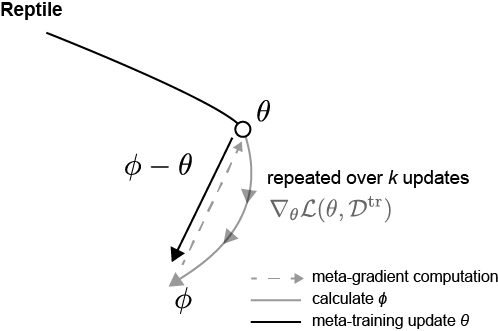 |
It might be confusing because the notation is different from the existing MAML paper, but explaining the process in detail is as follows:
- Initialize model parameter $\theta$
- Pick $N$ Tasks $\mathcal{T}_i$. (where $\mathcal{T}_i \sim p(\mathcal{T})$, batch = $N$)
- Inner Loop: FT for each task $\mathcal{T}_i$ (fine-tuned parameters: $\phi_i$)
- Outer Loop: Update $\theta$ by the difference between $\theta$ and $\phi$: $\theta \leftarrow \theta + \frac{\beta}{N}\sum_{i=1}^N (\phi_i - \theta)$
- repeat 2-4
When trained like this, ultimately the expectation value of the meta-gradient in the Reptile algorithm converges similarly to the meta-gradient of MAML. Most of the Reptile paper is content proving mathematically how it converges similarly to MAML and FOMAML. However, here we will only look briefly at the big context. I will also make a post related to proofs if I have the chance someday.
2.1.3 Wrap-up
Optimization-based Meta Learning is a meta-learning approach on how to utilize gradients for training when doing few-shot learning. Unlike other approaches, it has the advantage that if the gradient is set appropriately, it can be applied model-agnostically to various fields. In other words, it can be utilized in various fields such as Regression, classification, reinforcement learning, etc.
2.2 Metric-based Meta Learning
Metric-based meta-learning is literally a concept of training by calculating similarity based on distance. Simply put, there is semantic information that each class possesses, and training proceeds through the similarity between that semantic information. In a way, it can be seen as similar to the concept of nearest neighbors like $k$-NN. Representative examples include Matching Network, Prototypical Network, and Relation Network, and we will examine the main concepts discussed in each paper. (It would be good to keep the concept of Few-shot in mind.)
2.2.1 Matching Network
The first paper to look at is Matching Network. It is a pioneer paper in the metric-based approach. Thinking about the situation at that time, the seq2seq paper, which became the basis of the Transformer, had emerged. It is about training through the overall context, not just looking at extracted features through the Attention mechanism. Therefore, this paper intends to compare the context between features produced through an encoder.
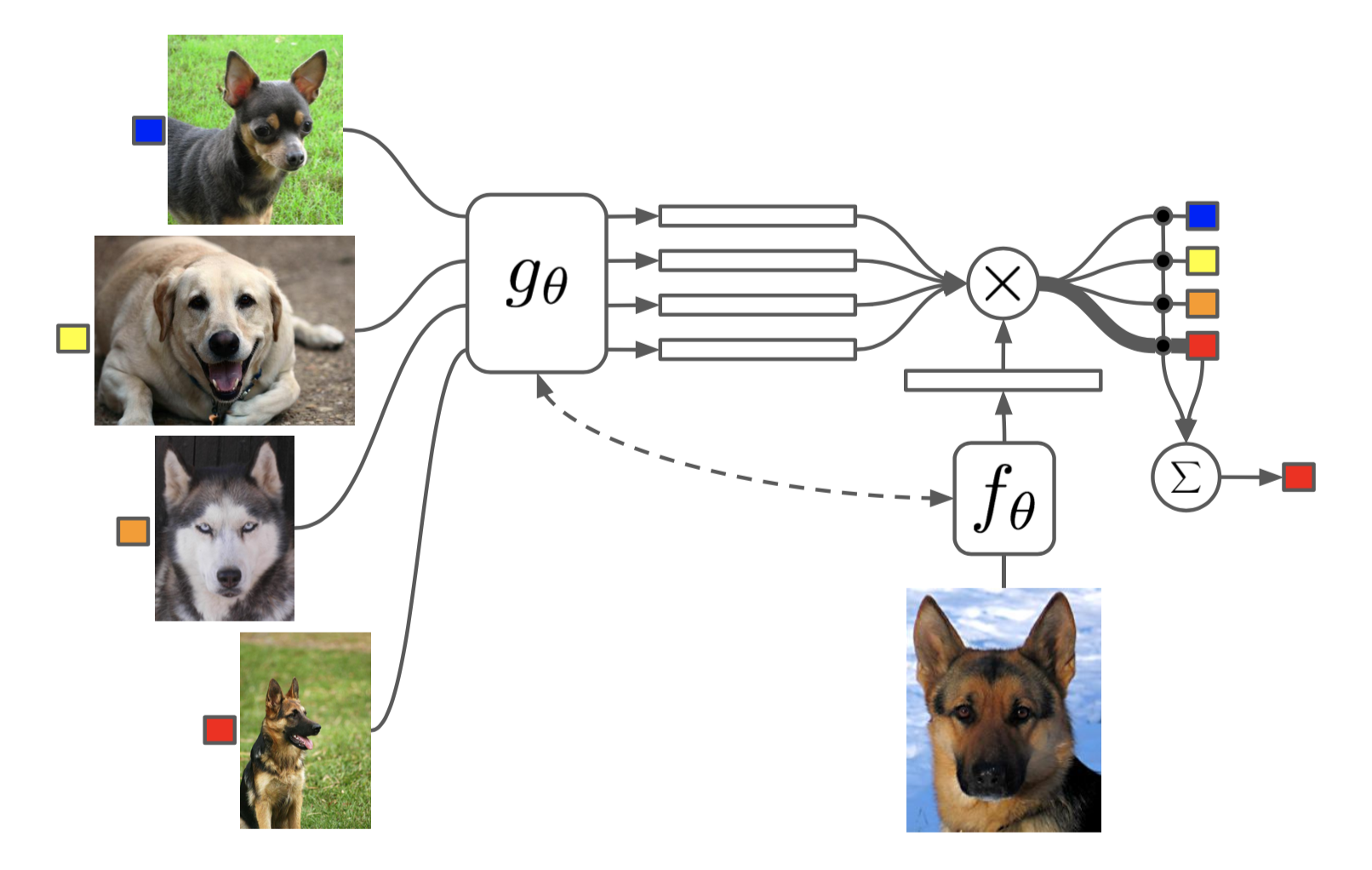
First, before explaining the training process, this paper explains the final output.
\[C_{\mathcal{S}}(\hat{\textbf{x}}) = P(y|\hat{\textbf{x}}, S) = \sum_{i=1}^k a(\hat{\textbf{x}}, \textbf{x}_i)y_i \; \;\; \text{where} \; \mathcal{S=\{ \text{(}\textbf{x}_i, y_i\text{)}\}_{i=1}^{k}}\]The formula above implies utilizing the attention mechanism by giving it more weight. Here, $a(\cdot, \cdot)$ is the attention kernel, which takes a softmax on cosine similarity:
\[a(\hat{x},x) =\frac{\exp(cos(f(\hat{x}), g(x)))}{\sum_{j=1}^k \exp(cos(f(\hat{x}), g(x_j)))}\]Interpreting the meaning above simply, it means calculating the similarity through the attention kernel for each support sample $\textbf{x}_i $ and input $\textbf{x}$, and then using this as a weight to predict towards the side with higher similarity when comparing. Here, you can understand input $\textbf{x}$ as a query sample.
Then let’s look at the training process with notation.
- Extract feature representation vector of support set through $g_\theta$
- Extract feature representation vector of query set through $f_\theta$ (Usually $f_\theta = g_\theta$)
- Calculate attention value between feature representation vectors from 1 and 2 $\rightarrow a(\cdot, \cdot)$
- Predict label of query set through $C_\mathcal{S}$
Unlike recent papers, early papers related to meta-learning utilized LSTM structures to solve the few-shot setting from a context perspective. So, this paper also proposed a method utilizing the LSTM structure additionally. ($\rightarrow$ Full Context Embeddings; FCE) Let’s see the FCE training process along with notation on how the LSTM model architecture is utilized.
- Embedding $g$
- $g \rightarrow $ bidirectional LSTM, $g’ \rightarrow$ CNN (feature extractor)
- $g(x_i, \mathcal{S})= \overrightarrow{h}_i + \overleftarrow{h}_i + g^\prime (x_i) $
- $\overrightarrow{h}_i,\overrightarrow{c}_i = \text{LSTM}(g^{\prime} (x_i), {\overrightarrow{h}}_{i-1}, {\overrightarrow{c}}_{i-1})$ , $\overleftarrow{h}_i,\overleftarrow{c}_i = \text{LSTM}(g^{\prime} (x_i), {\overleftarrow{h}}_{i+1}, {\overleftarrow{c}}_{i+1})$
- $f \rightarrow$ LSTM , $f’ \rightarrow$ CNN (feature extractor)
- $f(\hat{x}, \mathcal{S}) = \text{attLSTM}(f^\prime(\hat{x}), g(\mathcal{S}), K) $
$\Rightarrow$ According to $k$ step…
- $\hat{h}_k, c_k = \text{LSTM}(f^\prime (\hat{x}), [h_{k-1}, r_{k-1}], c_{k-1}) $
- $h_k = \hat{h}_k + f^\prime(\hat{x})$
- $r_{k-1} = \sum_{i=1}^{|\mathcal{S}|}a(h_{k-1}, g(x_i))g(x_i)$
- $a(h_{k-1}, g(x_i)) = \text{softmax}(h^\text{T}_{k-1}g(x_i))$
Ultimately, the reason for using LSTM here is to better view the context of each feature vector. In easy tasks like Omniglot, there is not much performance gain, but in slightly more difficult tasks like $mini$-ImageNet, there is performance gain.
2.2.2 Prototypical Networks
The next paper is Prototypical Networks (hereinafter ProtoNet). In fact, you can consider most metric-based meta-learning research as based on ProtoNet rather than Matching Network.
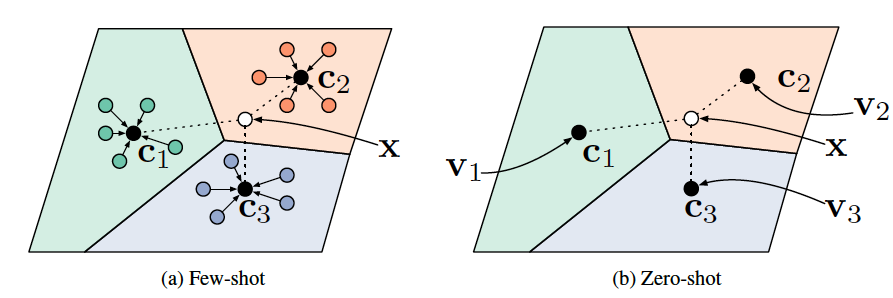
I’ll get straight to the point. ProtoNet proceeds with training through Euclidean distance calculation between the prototype vector of each label and feature vectors. Looking at Figure 6 below, $c_n$s represent the prototype of each label. So, for a new task, it calculates the distance with each prototype and maps it to the prototype label with the minimum distance. At this time, the prototype is obtained by the average of feature vectors derived from the support set. Then, let’s look at it in more detail through the following training process.
- Notation (I will explain as similarly to the paper as possible):
- Support Set $\mathcal{S}_{n}= \{ (x_{n,j}^s, y_{n,j}^s) \}_{j=1}^{K}$, Query Set $\mathcal{Q}_{n}= \{ (x_{n,j}^q, y_{n,j}^q) \}_{j=1}^{Q}$
- $K$: number of support set (a.k.a $K$-shot)
- $Q$: number of query set
- $c_n$: prototype of label $n$ $\rightarrow$ $\{c_1,\dots,c_N \}$, ($N$: $N$-way)
- $f_\theta$ : Model parameterized by $\theta$ (hereinafter feature extractor or backbone network)
- loss $\mathcal{L}(\mathcal{D},c,\theta) = \frac{1}{|\mathcal{D}|}\sum_{(x,y)\in \mathcal{D}} l(-d(f_\theta(x), c),y)$,
$\rightarrow$ loss function $l(\cdot, \cdot)$: Cross Entropy (CE), $-d(\cdot, \cdot)$: Euclidean Distance
- $c_n = \frac{1}{| \mathcal{S}_n |} \sum_{j=1}^{| \mathcal{S}_n |} f_\theta (x^s_{n, j}) \Rightarrow $ Calculate prototype vector ${c_n}$ with support set
- $\sum_{n=1}^{N}\mathcal{L}(Q_{n}, c_n, \theta) \Rightarrow$ Calculate Euclidean distance between query set and prototype $c_n$
- $\theta \leftarrow \theta - \nabla_{\theta}\sum_{n=1}^{N}\mathcal{L}(Q_{n}, c_n, \theta)$ $\Rightarrow$ model parameter update
Since there is quite a lot of notation and it’s complex, I think it might be difficult to understand. If the process is a bit complicated, it would be good to understand it simply as follows:
- Make a label called prototype with Support Set
- Compare distance between prototypes with Query Set $\Rightarrow$ Logits (Final output)
- Calculate CE between Query Set Label and Logits
- Update parameter with CE
This paper does not use a linear layer. Since feature vectors are directly used to find distance anyway, it is not used despite being a classification task. However, this paper explains that Euclidean distance can be reinterpreted like a linear model. I will explain while looking at the following two formulas.
\[-||f_\theta (x) - c_k||^2 = -f_\theta (x)^{\text{T}}\cdot f_\theta(x) +2c_k^{\text{T}}\cdot f_\theta(x) -c_k^{\text{T}}\cdot c_k \\\] \[2c_k^{\text{T}} \cdot f_\theta (x) - c_k^{\text{T}} \cdot c_k = w_k^{\text{T}}f_\theta(x) +b_k \;\; \text{where}\;\; w_k = 2c_k, \; b_k=-c_k^{\text{T}}c_k\]Actually, the reason why ProtoNet chose Euclidean distance over other distance metrics is here. The basic concept of Deep Learning is that if the backbone network performs feature representation smoothly, the rest only requires linear transformation suitable for the situation (especially classification tasks). Usually, in deep learning, this process is trained by attaching a learnable linear layer behind the backbone network. However, ProtoNet interprets that proceeding with training via Euclidean distance implies this linear transformation process. Also, another reason why it can be assumed that Euclidean distance is appropriate is that they claim parts requiring non-linearity during training have already been learned through the backbone network. Actually, this assumption is about the structure we take for granted: backbone model - linear layer. It seems mentioned in the paper since deep learning research was not as abundant at that time.
(Really lastly…) Another advantage when reinterpreted like this is that MAML (hereinafter Proto-MAML) can be applied to ProtoNet. Since $w_k^{\text{T}}f_\theta(x) +b_k$ acts as a linear layer, FT becomes possible. I will (briefly) explain the Proto-MAML training process.
- Notation:
- $f_\theta$: backbone network
- $g_\theta(x_i) = w_{i,k}^{\text{T}}f_\theta(x_i) +b_k$
- Loss $\mathcal{L}(\mathcal{D};\theta) = \frac{1}{|\mathcal{D}|}\sum_{(x,y)\in\mathcal{D}}l(g_\theta(x), y)$
- Inner Loop 1. Calculate prototype $c_{i,k}$ through support set $\mathcal{S}_i$
- $\phi = \theta - \alpha \nabla_\theta \mathcal{L}(\mathcal{S}_i;\theta)$
- Repeat $n$ steps
- Outer Loop: $\theta \leftarrow \theta - \frac{\beta}{\mathcal{B}}\sum_{i=1}^{\mathcal{B}}\nabla_\theta \mathcal{L}(\mathcal{Q}_i;\phi)$
Actually, there is a paper that proposed (fo-)Proto-MAML. If you read it, although it is not the very main concept in the paper, it showed that Proto-MAML has performance gain.
*Conclusion
Up to this post, I think I have covered almost all pioneer papers of meta-learning. Research on meta-learning exploded for about 4-5 years after 2016 and 2017 when the papers explained above appeared, and although it has decreased slightly now, it is still consistently published in top-conference papers. However, the trend has now changed from researching the meta-learning algorithm itself to applying it to other research. Especially, as foundation model research becomes extremely active, the concept of few-shot, which can train with a small amount of data, seems to have become more important.
As the next topic, I am thinking of posting about foundation models (LLM, LVM, etc.) that I have just started, whether it be paper reviews or concepts. I’m not sure which specific direction to take yet, but I will return after studying to some extent. Thank you for reading.